
For the past couple of years I’ve been refining a workflow to convert MS Word files into publishable TEI. By “publishable” I mean TEI that can be loaded into some existing publication system (something like TEI Publisher, Edition Visualization Technology (EVT), or TEI Boilerplate), or that you could process yourself in some other way.
Why might you want to use such a workflow? In my experience, it’s useful when you have a person or people who are designated as transcribers, but who aren’t comfortable or interested in encoding in XML. Microsoft Word is ubiquitous, so pretty much everyone in academia uses it and has access to it. For people who don’t want to work with pointy brackets but still want to collaborate on a digital editing project, a workflow that converts Microsoft Word to TEI can be very useful. (I have also used this workflow myself, even though I’m capable of hand-encoding XML, just because there are times when I’d rather just to it in Word. YMMV!)
I think the workflow works best when there is one person designated to do all the conversion at the end (steps 4 and 5) and any number of people involved in the first three steps. The workflow could be used in the classroom as a group project (where the students model the TEI, plan the pseudocodes, and do the encoding, and one student or the instructor does the conversion work at the end) although I’ve only used it for non-classroom editing projects.
There are a few things you need in order to be successful with this workflow:
- You need a team that knows TEI. This doesn’t mean they need to know XML! (Although yes, you will need someone on your team who knows XML, but that’s not related to TEI) You need to know TEI basics – what tags and attributes are, how modules and classes work – and you need these because you need to know what TEI tags you want in your final document before you start transcribing.
- Microsoft Word (obviously)
- OxGarage conversion tools. OxGarage is a service of the Text Encoding Initiative, which provides scripts for converting between a variety of text formats, including MS Word to TEI.
- OxygenXML Editor (or an XML editor of your choice). OxygenXML is popular with the TEI community, and it has the find & replace functionality that is required by this workflow. BBEdit is another XML/text editor that I use a lot, and it has a great find & replace functionality, but it doesn’t work as well for this workflow for reasons I’ll describe later in this post.
The steps of the workflow are (briefly):
- Model your TEI.
- Create pseudocodes to “tag” in MS Word.
- Transcribe in MS Word, using the pseudocode “tags” to indicate those things that will eventually be converted into TEI.
- Convert the finished MS Word document into TEI using OxGarage.
- Use find & replace in OxygenXML to convert the pseudocode tags into TEI tags, resulting in well-formed and complete TEI.
In more detail:
Model your TEI
The very first thing you need to do is to decide what you need your finished TEI to be able to do. If you’re working with an existing system (e.g., if you know you’ll be publishing in EVT at the end) some of your decisions will be made for you, because you will need to have TEI code that the system can use.[1] Are you encoding abbreviations, and if so are you going to tag the entire word or just the abbreviation and expansion? Are you going to normalize spelling, and if so are you going to do it silently or tag it? Are there marginalia you want to include in your TEI code? Do you want to include editorial notes?
Make a list of everything you need in your TEI, which TEI tags you plan to use, and how you plan to use them. You’ll need this to do the next step of the workflow, the creation of pseudocodes.
Create pseudocodes and tag them in MS Word
Pseudocodes are what I call non-TEI formatting elements that are used to set text apart, and are later processed into TEI tags. Pseudocodes can be divided into two main types: native MS Word formatting (italics, underlining, superscript, etc.) and punctuation marks.
Native MS Word Formatting

MS Word formatting is converted by OxGarage into TEI <hi> tags with the relevant values for @rend. For example, Italics converts to <hi rend=“italic”>Italics</hi>, Bold converts to <hi rend=”bold”>Bold</hi rend=”bold”>, Underscore converts to <hi rend=“underline”>Underscore</hi>, Strikethrough converts to <hi rend=“strikethrough”>Strikethrough</hi>, Red text converts to <hi rend=“color(FF0000)”>Red text</hi>, Yellow highlight (not an option in WordPress) converts to <hi rend=“background(yellow)”>Yellow highlight</hi>,Superscript converts to <hi rend=“superscript”>Superscript</hi>, and Subscript converts to<hi rend=“subscript”>Subscript</hi>.

This is of course useful if you want these exact tags reflected in your final TEI, but once the TEI comes out of OxGarage, you can use the find and replace function in OxygenXML (or some other text/XML editor) to convert these tags into other tags. More on this below.
Native MS Word formatting works very well and can represent a very large number of TEI tags (using just text color and highlight would give you 75 pseudocodes mapping to 75 TEI tags or tag/abbreviation combinations), but there are definitely cases when you would want to use punctuation marks instead.
Punctuation Marks
You can use punctuation marks to set text apart that might not correspond 1:1 with a TEI tag. These are cases, such as expanded abbreviations or corrected readings, where you need tags nested within tags. Brackets work particularly well for this, especially various combinations of brackets. You do need to be careful about configuring bracket combinations, particularly when you’ll have brackets nested within brackets, and (as will also be mentioned later) the order in which you find & replace brackets later will also be relevant. This isn’t a matter to be taken lightly. You should test your pseudocodes and find & replace expressions on a section of text before encoding a full text.
Here is an example using the first line of Genesis 3, from University of Pennsylvania MS. Codex 236, fol. 31r

The text in this line reads:
sed et serpens erat callidior cūctis aīantib t̄
This includes a number of abbreviations that we could expand silently, or we could encode them in TEI in a few different ways. (For more information see the TEI Guidelines 11.3.1.2, “Abbreviations and Expansion”) Options include:
Noting that a word contains an abbreviation, without expanding it. In this example we put <abbr> tags around the complete word, and <am> tags around the abbreviated letter:
sed et serpens erat callidior <abbr>c<am>ū</am>ctis</abbr> <abbr>a<am>ī</am>anti<am>b</am></abbr> <abbr><am>t̄</am>…</abbr>
In word, you might choose pseudocodes using nested brackets. In this case, [[]] will be converted later into <abbr></abbr>, and [] (nested within [[]]) will be converted to <am></am>:
sed et serpens erat callidior [[c[ū]ctis]] [[a[ī]antib]] [[[t̄]…]]
Alternatively, you might choose to encode both abbreviation and expansion, and enable the system to choose between them. In this example we add <expan> and <ex> tags to the mix alongside <abbr> and <am>, and then include <choice> to make it clear that the abbreviations and expansions come in pairs.:
sed et serpens erat callidior
<choice>
<abbr>c<am>ū</am>ctis</abbr>
<expan>c<ex>un</ex>ctis</expan>
</choice>
<choice>
<abbr>a<am>ī</am>anti<am>b</am></abbr>
<expan>a<ex>nim</ex>antib</expan>
</choice>
<choice>
<abbr><am>t̄</am>…</abbr>
<expan><ex>ter</ex></expan>
</choice>
As above, you can come up with combinations of marks that you can use to indicate the encoding. In this case <abbr> and <am> are encoded as above, || will later be converted to <choice>, {{}} will be converted later into <expan></expan>, and {} (nested within {{}}) will be converted to <ex></ex>:
sed et serpens erat callidior |[[c[ū]ctis]]{{c{un}ctis}}| |[[a[ī]anti[b]]]{{a{nim}anti{bus}}}| |[[[t̄]]]{{{ter}…}}|
I like to group brackets of the same type together (as here, where square brackets are used for abbreviations, curly brackets for expansions, and pipes for choice) but you can also combine them in various ways for more options. For example, here are the bracketing options for a project I’m currently working on:

In all cases you need to be very careful that the punctuation marks you use don’t appear in your text, or only use them in combinations that don’t appear in your text, or else you will accidentally create TEI tags where you don’t want them.
Convert Word to TEI in OxGarage
Once you’ve transcribed and entered pseudocodes in MS Word, it’s time to convert your Word file into TEI. You can do this using OxGarage, a conversion service provided by the TEI. OxGarage has an online interface where you can convert one document at a time, described here, but you can also download the XSLTS from GitHub and run bulk conversion processes (converting multiple files at one time).
The online OxGarage interface is at http://www.tei-c.org/oxgarage/. 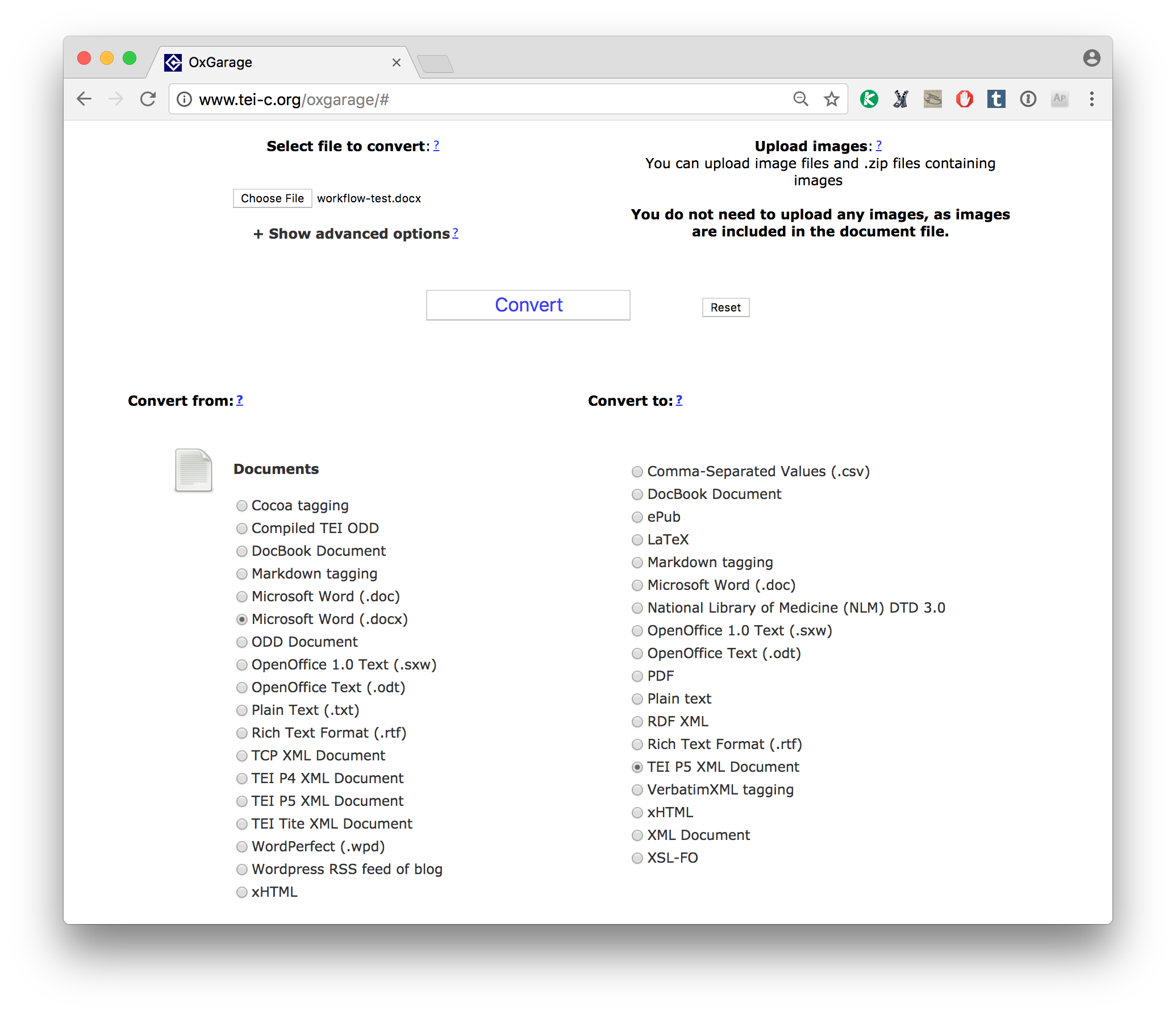 You need to indicate that you are converting Documents, then select your options from (Microsoft Word doc or docx) and to (TEI P5), then load in your Word document and click “Convert”. Here is my input file (so you can download it and try this yourself), and a screenshot:
You need to indicate that you are converting Documents, then select your options from (Microsoft Word doc or docx) and to (TEI P5), then load in your Word document and click “Convert”. Here is my input file (so you can download it and try this yourself), and a screenshot: 
OxGarage will generate a TEI file with a template header (including information gleaned from the Word document) and the textual content of the Word doc converted into very basic TEI (file here; you’ll need to change the file extension to .xml):
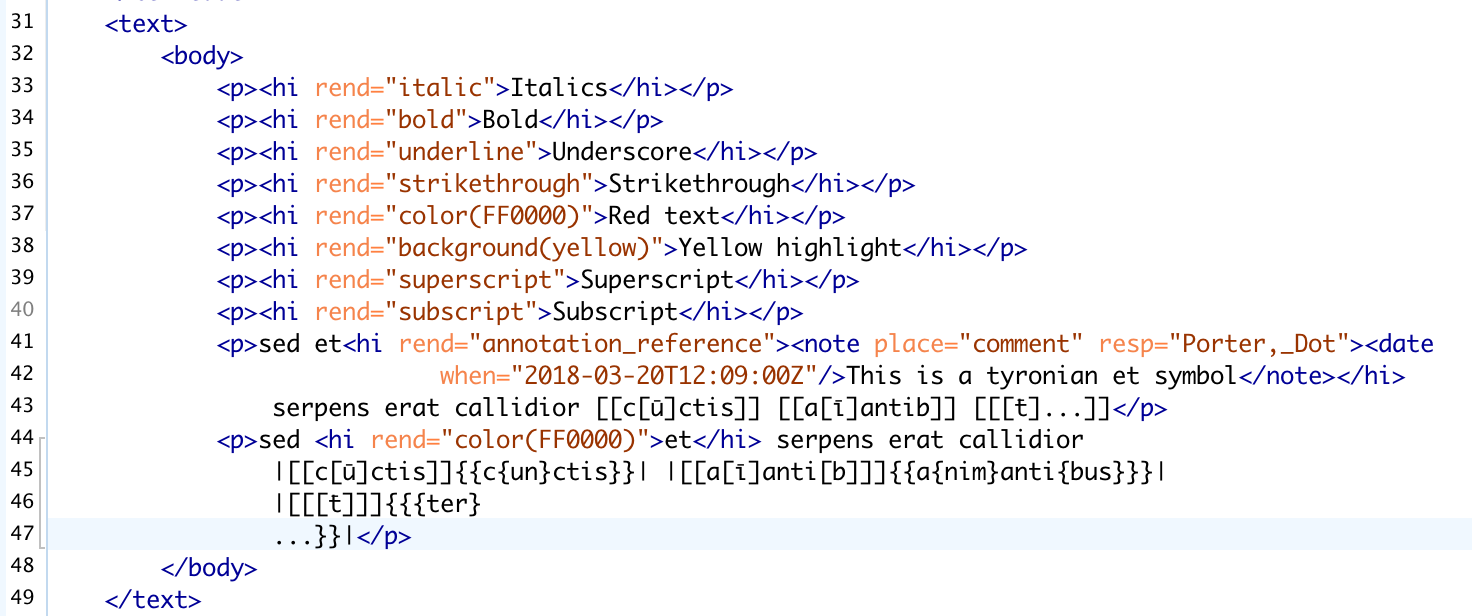
You can see here how the Word comment is converted into a <note> nested in <hi>, with a <date> included. I also included some red text (to indicate the tyronian et symbol) which has converted as expected. The punctuation mark pseudocodes are unchanged.
Replace Pseudocodes with TEI Tags
This is where we replace those pseudocodes – the <hi> color tags and the combinations of punctuation marks – into TEI. I like to do this in OxygenXML, because that software has advanced and advanced find & replace that enables you to search using regular expressions, including the ability to save pieces of what is being searched and reusing that in the replace (a bit like setting a variable in the search).[2]
As mentioned above the order in which you replace tags matters. You will always want to replace the outermost pseudotags first, then the interior ones, because the find & replace will always match from the first instance of a character in the regular expression to the last instance. This means that if you have […] (for <am>) nested inside [[…]] (for <abbr>) you need to replace the [[…]] before the […] or else you will end up with <am> around the word, and there will be no match when you then search for [[…]].
For example, to find [[…]] and replace it with <abbr>, using Find/Replace with the “Regular Expression” and “Dot matches all” boxes checked, you would search for:
\[\[([^\s]*)\]\] (this is a regular expression that will find every instance where a string of any character except spaces (\s), enclosed by [[ and ]] . The central part of the expression is enclosed with parentheses because we’re going to reuse that in the replace. The square brackets are preceded by \ to ensure they are considered as characters and not as part of a regular expression)
And replace that with
<abbr>$1</abbr> (This will replace the [[ and ]] with the closing and ending tags, and copy everything else in the middle – $1 refers to the piece of the search that was enclosed in parentheses)
Unfortunately, if you have an abbreviated word that starts on one line and ends on the following line (as we do here – the last word on this line is terre, but the re are on the next line) this regular expression won’t catch it because it ignores all spaces. So I do two sets of finds for each set of pseudocodes: one using the expression above, which ignores spaces, and a second one which includes spaces.
\[\[(.*)\]\] (replace with <abbr>$1</abbr>) as above
You don’t want to include spaces in your first search because if you have multiple sets of the same pseudocode in your document (which you probably do), the regular expression will include all the spaces so will only find the very first and the very last instance of the double brackets and you’ll end up with this:

The regular expression has matched the first [[ (on line 43) and the last]] (on line 46), but there are many in between that are missed because spaces are included.
Starting with the first search followed immediately with the second gives you:

Similarly, tag abbreviations by replacing |…| with <choice>…</choice> and {{..}} with <expan>…</expan> – all the outer nesting has been replaced with TEI tags:

When you have multiple codes that may be nested in a single tag (as the multiple [] and {} now within <abbr> and <expan>) you need to modify the regular expression again, so it catches every matching pair of brackets.
\{([^\s\}]*)\} (Note the \} now within the square brackets. This will keep the expression from moving past the first closing bracket)
The result is a complete set of TEI tags encoding abbreviations and expansions (result file here, change the file extension to .txt).

You can also use OxygenXML’s find & replace function to replace the pseudocode TEI tags, or you can be fancy and write an XSLT to do that work.  In this example, I want to replace the <hi rend=”color(FF0000)”> with <g ref=”#t_et”> (I’ll add a corresponding <glyph> tag to the <charDecl> section of the header as described in 5.5.2 of the TEI Guidelines). This is fairly straightforward, since I know the content of the tag will always be “et” I can do a find & replace for the whole thing. If the content of the tag varies, I can use a regular expression as I did above to copy content from find to replace.
In this example, I want to replace the <hi rend=”color(FF0000)”> with <g ref=”#t_et”> (I’ll add a corresponding <glyph> tag to the <charDecl> section of the header as described in 5.5.2 of the TEI Guidelines). This is fairly straightforward, since I know the content of the tag will always be “et” I can do a find & replace for the whole thing. If the content of the tag varies, I can use a regular expression as I did above to copy content from find to replace.
And that’s the workflow. It’s still a lot of work, you need a strong handle on the TEI and you need to plan everything in advance. But if you are working with a large number of people transcribing and advanced TEI training isn’t possible or desirable.
[1] EVT for example has specific requirements for tags it can process and how those tags need to be formatted, and if your TEI doesn’t meet those requirements it won’t work out of the box – you’ll need to modify the EVT code to suit your TEI.
[2] For more information and tutorials on Regular Expressions, visit https://regexone.com/.